Scientific Evaluation
at Scale
A research tool that quantifies abstract concepts from verbal or text data using AI-driven creation, customization, and deployment of measurement models.
Why Current Methods Fall Short
Researchers face a fundamental dilemma when analyzing text data at scale
Existing Methods Don't Scale
- Manual coding is slow, expensive, and challenging to scale
- Keyword matching misses nuance in theoretical constructs
- Sentiment analysis lacks context
- Custom ML models require labeled data researchers don't have
LLMs Lack Scientific Defensibility
- Naive LLM outputs are unreliable due to randomness, position bias, and prompt sensitivity
- Minor prompt changes can shift results dramatically
- Raw LLM outputs lack the reliability and rigor required by academic journalslack reliability
There's a better way
Copernicus
Four pillars that make AI-powered text evaluation scientifically defensible
Concept-Agnostic Framework
Operationalize any theoretical construct into a structured evaluation model
Collaborative Refinement
Co-create, validate, and replicate measurement instruments with domain experts
Research-Informed Rubrics
AI-assisted construction leveraging existing literature and frameworks
Variance-Aware Protocol
Prompt ensembles × repeated sampling = quantified uncertainty
From Concept to Model
A structured four-step process to operationalize any theoretical construct
Concept Definition
Define the abstract concept you want to measure
Methodology Choice
Select appropriate measurement approach
Concept Factorisation
Break down into measurable dimensions
Model Creation
Build and validate your evaluation model
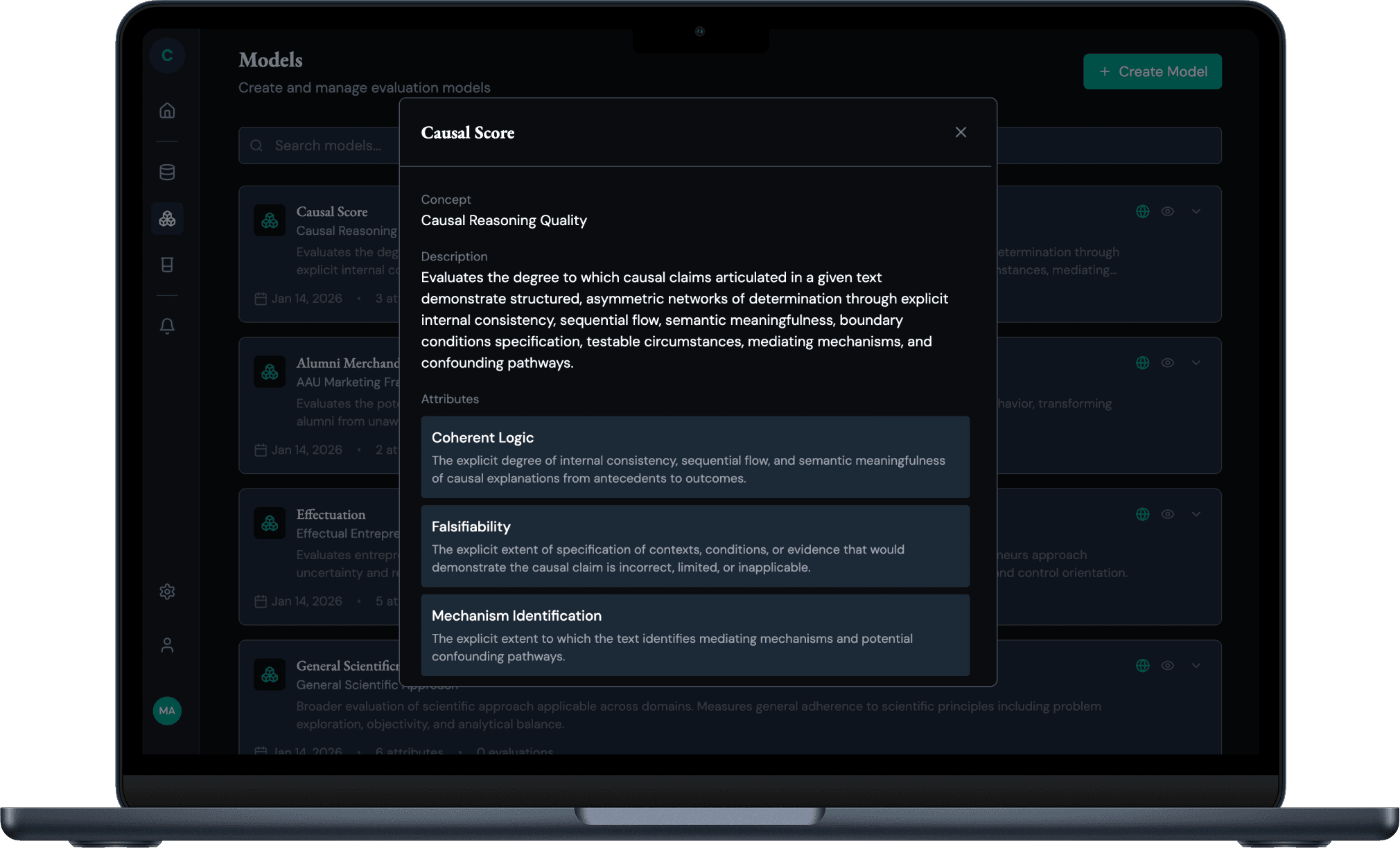
Example: Measuring "Scientificness"
Objectivity & Transparency
- Explicit Assumptions
- Fact vs Opinion
Flexibility/Rigidity
- Seeking Conflicting Data
- Adaptability
Bias Awareness
- Bias Toward Initial Beliefs
- Neutrality
Holistic Approach
- Integrated Wholes
- Component Examination
Powerful Research Tools
Everything you need to build, test, and deploy measurement models at scale
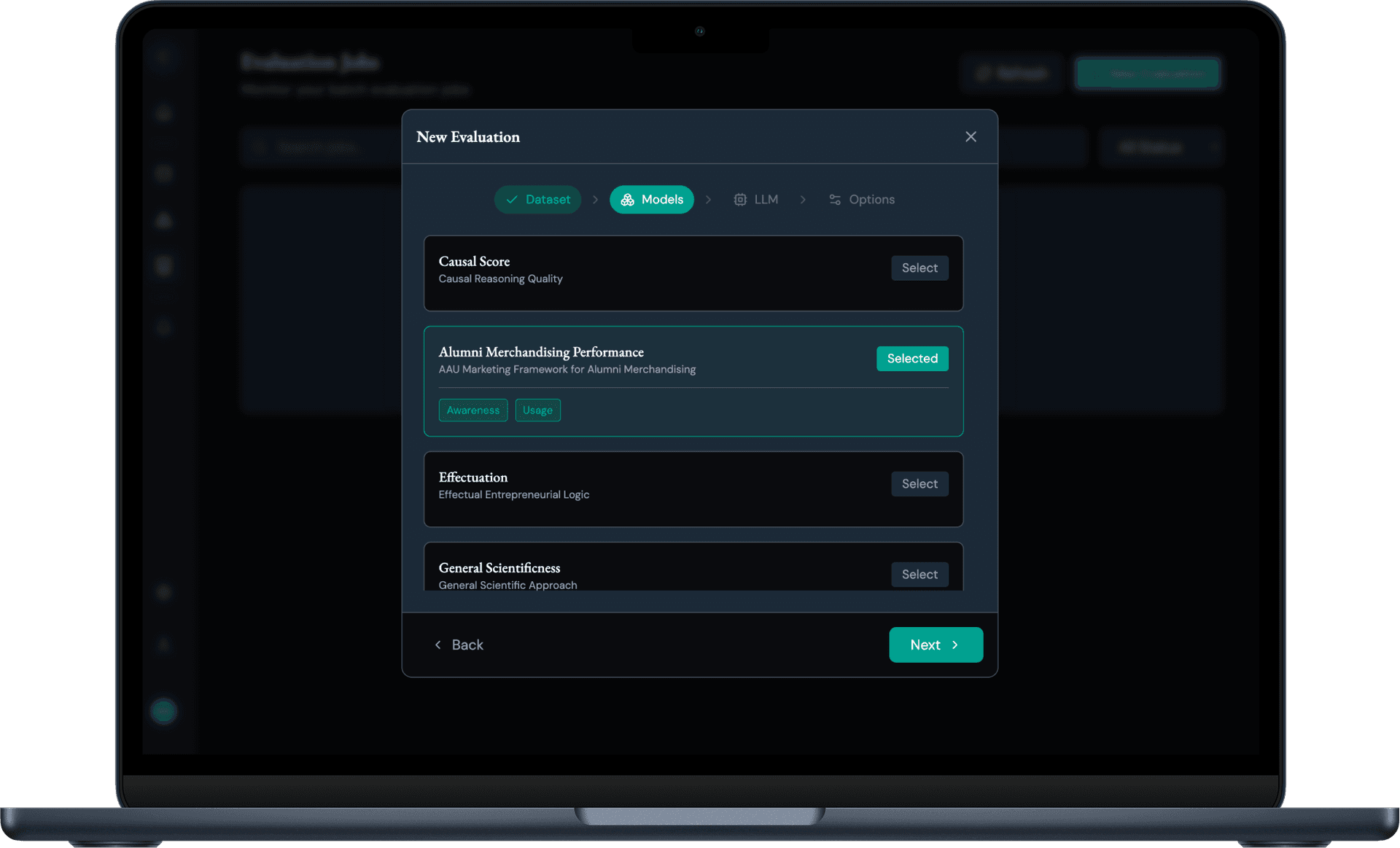
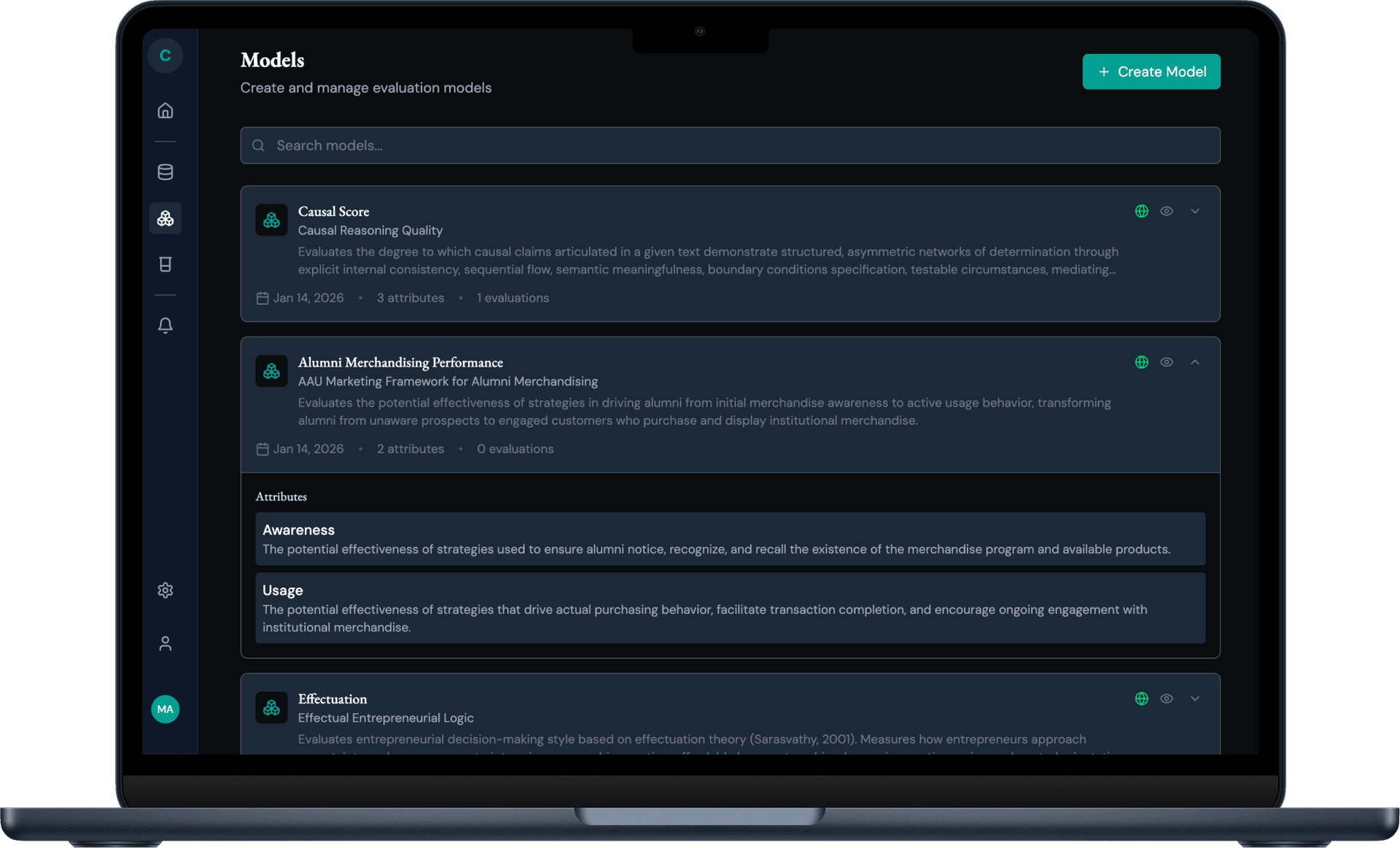
Model Library
Create and manage evaluation models with customizable attributes. Collect and reuse your models alongside public models from the research community.
- Create & manage models
- Define attributes
- Share with community
- Explore public models by concept, area, method
- Version history & team sharing
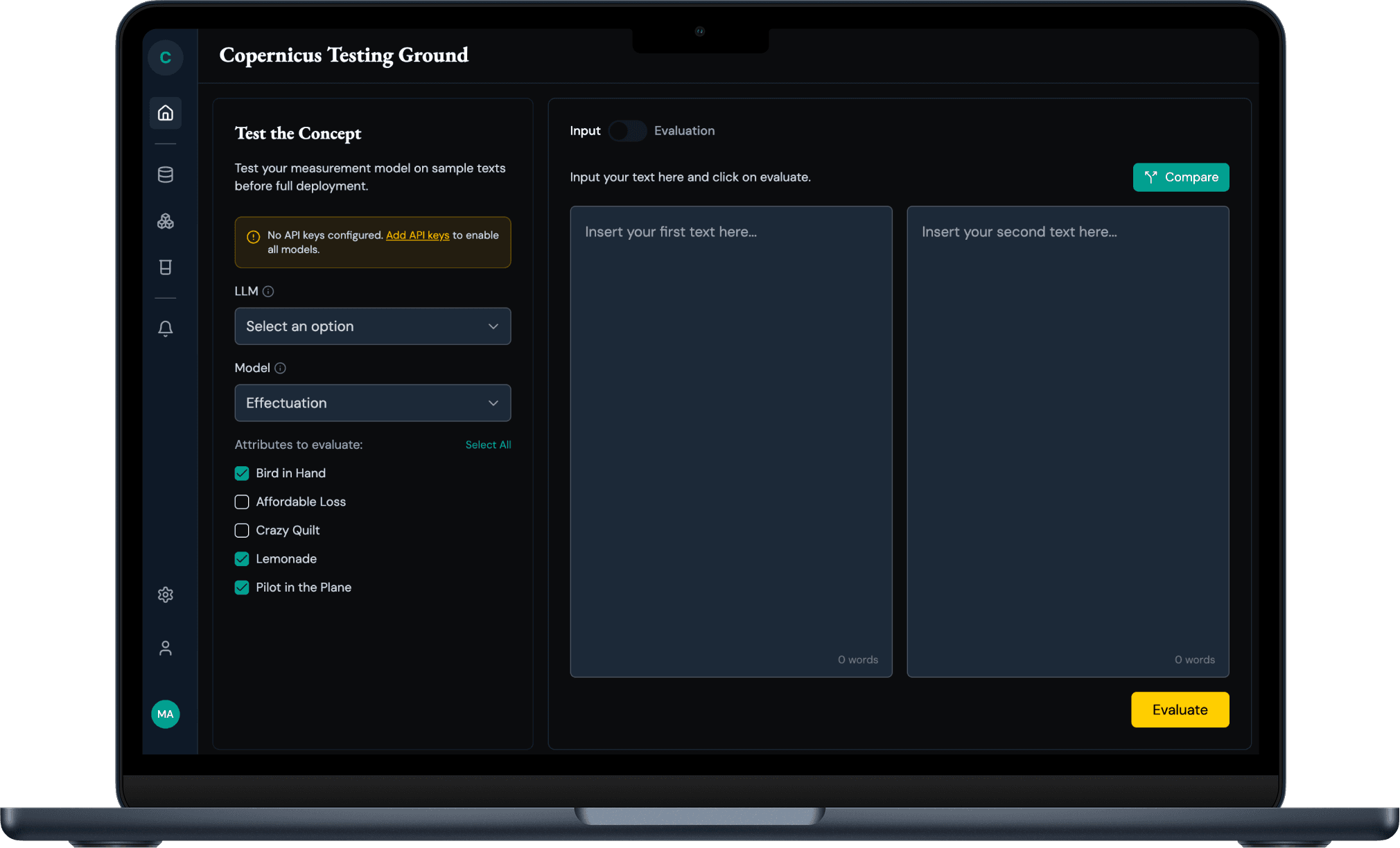
Testing Ground
Test your measurement model on sample texts before full deployment with side-by-side comparisons.
- Side-by-side comparison
- LLM selection
- Attribute-level testing
Evaluation Ground
Run large-scale evaluations with variance-aware protocols and quantified uncertainty.
- Protocol mode
- Prompt variants
- Cost estimation
Six Core Research Applications
One platform powering diverse research methodologies
Construct Measurement
Score texts against theoretical frameworks
e.g., Measure 'scientificness' in strategic documents
Content Analysis
Classify themes across document corpora
e.g., Categorize customer feedback by topic
Quality Assessment
Evaluate writing against standards
e.g., Assess research paper rigor
Behavioral Coding
Identify decision-making patterns in text
e.g., Analyze interview transcripts
Training Data Generation
Create labeled datasets for ML models
e.g., Generate high-quality annotations
Comparative Studies
Benchmark across groups with statistical rigor
e.g., Compare leadership styles across industries
Ready to Scale Your Research?
Transform how you measure abstract concepts from text. Get scientific defensibility without sacrificing scale.